
The aim of this project is to practice the application of programming design, principles, and architecture, by developing various back-end framework modules using only native Java libraries. The project is designed to incorporate many fields of computer science, including a command-line interface, server networking, service management, concurrent processing, data handling, event logging, machine learning, and distributed computing, among other fields.
It is designed to be as streamlined as possible, and is currently composed of ~140 classes with ~20000+ lines of code. Ultimately I would like to rewrite the whole project in C++ once I become competent at it.
This project originally started when I wanted to create a command-line console framework for Java applications, to allow for developers and power users to interact with an application directly through typed commands. From there, a hierarchical database was created to allow for named access to objects. Then, I decided to try and implement the command-line console to be network transparent, allowing for console access to server machines over a network. At this point, I realized I could use my framework to perform distributed computing, allowing a collection of computers to act as a supercomputer. As I started getting into machine learning, I decided to focus on developing the system into a distributed framework focussed on machine learning.
Modules I’ve worked on include:
Local Application Server
Remote Application Server
Event Logging
Object Database
Command-line Interface
Network Interface
Services Manager
Distributed Computing
Machine Learning Module
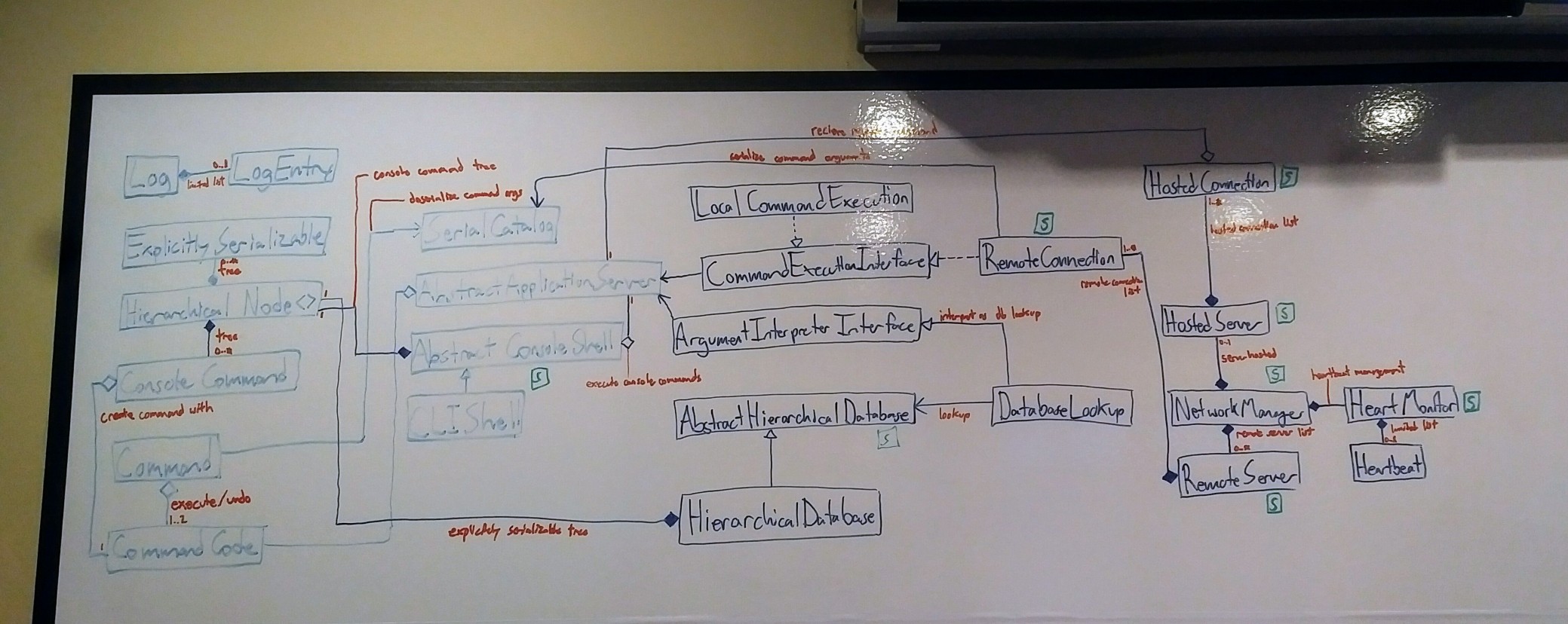
The local application server is the base, containing defined commands which interface with the main Java application. These commands are implemented as classes which are executed by public methods implemented by the application server class. The local application server is useless by itself, but it can be extended with the other modules.
The remote application server allows for perfectly network transparent access to the local application server on a remote machine. This allows for very easy implementation of cluster computing.
The event logging module is intended for keeping organised log entries for all the other modules, including handling exception stack traces for application error reporting and bug-fixing. Combined with the command-line interface part of this project, the output and events of a local or remote applications can be monitored live.
The object database provides a hierarchical database for named objects, very similar to the Windows Registry. It writes to disk using explicit Java serialization, either as individual named object files, or chunked binary files. Having named objects allows for them to be passed as command parameters when using a command-line interface, or for primitive variables to be modified by name. Finally, the object database handles automatic serialization and deserialization caching for massive objects, of which many cannot fit in memory.
The command-line interface allows for the local application server’s commands to be executed from the command line. Either name referenced database objects or parsed primitive values can be used as parameter arguments. The event logging module is mostly used for application text output, but defined commands can output text directly as well. This allows for segregation between program output and messages which are directly intended for the user. In addition to the remote application server being a network transparent local application server, the command-line interface of remote machines is also network transparent, allowing for one machine to act as a console to another.
The network interface provides a layer of network transparency, allowing a local application server or text interface to be accessed over a network, as if it were on the local machine. Server heartbeat is used to automatically find other networked applications on the local network, and test their speed and availability. Just like the database, it uses my explicit Java serialization for serializing objects over the network, using the smallest number of bits possible without compression. It even works with link-local connections, so two computers directly connected with an Ethernet cable will automatically interface with each other.
The services manager keeps track of services which are currently running or can be run. It can restart services should they fail, and allows for services to be gracefully or forcefully stopped. It is mostly used for managing services that a server implementation would provide, but is also used for local services. Other modules in this project are implemented as services, such as the database and network manager, which makes the system very robust as a whole. It is very similar to Windows services.
The distributed computing module allows for distributed services to be easily implemented, which automate the process of sending data to a remote server, running a remote service, and retrieving the data.
The machine learning module currently includes training long short-term memory neural networks using a evolutionary algorithms. I plan on abstracting this module to focus on statistics in general, and make use of OpenCL for quicker processing.
I’m planning for my lightweight flexible GUI to automatically generate graphical interfaces from an application implementing the shell framework, allowing for any defined command to be executed through the generated GUI.

